
在现代应用开发中,数据库选择往往是一个关键决策。对于许多场景来说,引入完整的关系型数据库管理系统可能显得过于重量级,而 SQLite 作为一款轻量级的嵌入式数据库,恰好提供了一个平衡的解决方案。本文将详细介绍 SQLite 的核心概念,并深入探讨 Node.js 生态中最受欢迎的 SQLite 绑定库——better-sqlite3。
什么是 SQLite#
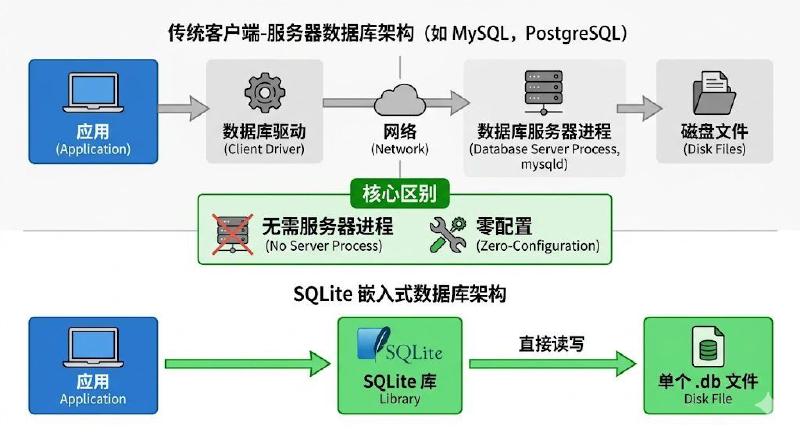
SQLite 是一个轻量级的、嵌入式的、关系型数据库管理系统,由 D. Richard Hipp 于 2000 年发布。与传统数据库(如 MySQL、PostgreSQL)需要独立的服务器进程不同,SQLite 直接将数据库存储在单个文件中,应用程序通过动态链接库直接访问数据。
SQLite 的核心特点#
零配置部署 SQLite 不需要安装、不需要配置、不需要管理。用户只需引入一个动态库文件,即可开始使用数据库。这使得 SQLite 成为嵌入式系统和小型应用的理想选择。
单一文件存储
整个数据库(包括表、索引、数据)都存储在一个独立的 .db 或 .sqlite 文件中。这个特性带来了几个显著优势:数据库易于备份、可以轻松在不同机器间转移、支持原子文件系统快照。
事务支持 SQLite 完全支持 ACID 事务特性,确保数据操作的原子性、一致性、隔离性和持久性。即使在系统崩溃或断电的情况下,数据库也能保持一致性。
跨平台兼容 SQLite 支持几乎所有主流操作系统,包括 Windows、macOS、Linux、iOS、Android 等。数据库文件可以在不同平台间自由迁移。
SQLite 的适用场景#
SQLite 特别适合以下场景:
- 嵌入式应用:移动应用、物联网设备、桌面软件
- 小型网站:流量适中的个人博客、小型管理系统
- 开发测试:快速原型开发、本地开发环境
- 数据缓存:作为应用数据的本地缓存层
- 数据分析:处理中等规模的数据集分析
SQLite 的局限性#
当然,SQLite 也有一些固有限制:
- 并发写入限制:SQLite 的写操作是串行化的,高并发写入场景不适合
- 单文件限制:整个数据库在单个文件中,不适合超大规模数据
- 功能限制:不支持存储过程、触发器等高级特性(最新版本已支持部分功能)
为什么选择 better-sqlite3#
在 Node.js 生态中,有多个 SQLite 绑定库可供选择,包括 sqlite3、better-sqlite3、sql.js 等。其中,better-sqlite3 以其独特的同步 API 设计和卓越的性能表现脱颖而出。
better-sqlite3 的核心优势#
同步 API 设计 better-sqlite3 提供完全同步的 API,这与 Node.js 传统的异步编程模型形成了鲜明对比。同步 API 并不意味着阻塞——实际上,better-sqlite3 的底层实现经过高度优化,在大多数场景下比异步版本更快。同步 API 的主要优势在于代码逻辑更加清晰,避免了回调地狱问题。
const Database = require('better-sqlite3');
const db = new Database('app.db');
// 同步执行,无需回调
const users = db.prepare('SELECT * FROM users WHERE active = ?').all(1);
console.log(users);卓越的性能表现 根据多个基准测试,better-sqlite3 是 Node.js 中性能最高的 SQLite 库。它通过以下方式实现高性能:
- 预编译 SQL 语句缓存
- 减少函数调用开销
- 优化的内存管理
- 原生 C++ 绑定
完整的类型支持 better-sqlite3 对 JavaScript 类型与 SQLite 类型的映射处理得非常完善,支持 null、integer、real、text、blob 等类型。
丰富的 API 除了基础的 CRUD 操作,better-sqlite3 还提供了:
- 预处理语句(Prepared Statements)
- 事务支持
- 批量操作
- 数据库备份
- WAL 模式支持
与其他库的对比#
| 特性 | better-sqlite3 | sqlite3 | sql.js |
|---|---|---|---|
| API 风格 | 同步 | 异步 | 异步 |
| 性能 | 最快 | 中等 | 较慢 |
| 依赖 | 原生模块 | 原生模块 | 纯 JavaScript |
| 浏览器支持 | 否 | 否 | 是 |
| 预编译缓存 | 内置 | 手动 | 手动 |
核心 API 详解#

数据库连接#
const Database = require('better-sqlite3');
// 内存数据库(数据不持久化)
const memDb = new Database(':memory:');
// 文件数据库
const fileDb = new Database('app.db');
// 带选项的初始化
const db = new Database('app.db', {
verbose: console.log, // 输出 SQL 语句到控制台
fileMustExist: true, // 文件不存在时抛出错误
readonly: false, // 只读模式
});基础 CRUD 操作#
插入数据
const stmt = db.prepare('INSERT INTO users (name, email, age) VALUES (?, ?, ?)');
const result = stmt.run('张三', 'zhangsan@example.com', 25);
console.log(result.changes); // 影响的行数
console.log(result.lastInsertRowid); // 最后插入的 ID
查询数据
// 查询单条记录
const user = db.prepare('SELECT * FROM users WHERE id = ?').get(1);
// 查询多条记录
const users = db.prepare('SELECT * FROM users WHERE age > ?').all(18);
// 查询单个值
const count = db.prepare('SELECT COUNT(*) FROM users').value();
// 使用命名参数
const stmt = db.prepare('SELECT * FROM users WHERE name = @name AND age > @minAge');
const result = stmt.all({ name: '张三', minAge: 20 });更新数据
const stmt = db.prepare('UPDATE users SET email = ? WHERE id = ?');
const result = stmt.run('newemail@example.com', 1);
console.log(result.changes);删除数据
const stmt = db.prepare('DELETE FROM users WHERE id = ?');
const result = stmt.run(1);预处理语句#
预处理语句是 better-sqlite3 的核心特性之一。它们被预编译并缓存,可以显著提升重复查询的性能。
// 创建预处理语句
const insertUser = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
const selectUser = db.prepare('SELECT * FROM users WHERE id = ?');
// 多次使用
insertUser.run('用户A', 'a@example.com');
insertUser.run('用户B', 'b@example.com');
const user = selectUser.get(1);事务处理#
// 自动提交模式(默认)
db.prepare('INSERT INTO users (name) VALUES (?)').run('用户A');
// 手动事务
const insertUser = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
const insertPost = db.prepare('INSERT INTO posts (title, user_id) VALUES (?, ?)');
try {
// 开始事务
db.exec('BEGIN TRANSACTION');
insertUser.run('新用户', 'new@example.com');
const userId = db.prepare('SELECT last_insert_rowid() as id').get().id;
insertPost.run('我的第一篇文章', userId);
// 提交事务
db.exec('COMMIT');
} catch (error) {
// 回滚事务
db.exec('ROLLBACK');
console.error('事务失败:', error);
}
// 使用 transaction 辅助方法(更简洁)
const insertUser = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
const insertPost = db.prepare('INSERT INTO posts (title, user_id) VALUES (?, ?)');
const createUserWithPost = db.transaction((name, email, postTitle) => {
const userResult = insertUser.run(name, email);
const userId = db.prepare('SELECT last_insert_rowid() as id').get().id;
insertPost.run(postTitle, userId);
});
createUserWithPost('新用户', 'new@example.com', '第一篇文章');数据库备份#
// 备份到另一个文件
db.backup('backup.db');
// 或者使用流式备份
const backup = db.backup();
const destination = require('fs').createWriteStream('backup.db');
backup.pipe(destination);WAL 模式#
Write-Ahead Logging(WAL)模式可以显著提升并发读取性能:
db.pragma('journal_mode = WAL');
db.pragma('synchronous = NORMAL');
db.pragma('cache_size = -64000'); // 64MB 缓存
实战示例:构建一个简单的任务管理系统#
下面我们将使用 better-sqlite3 构建一个完整的任务管理示例。
初始化数据库#
const Database = require('better-sqlite3');
const db = new Database('tasks.db');
// 创建表
db.exec(`
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT,
status TEXT DEFAULT 'pending',
priority INTEGER DEFAULT 0,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP
)
`);
// 创建索引
db.exec(`
CREATE INDEX IF NOT EXISTS idx_tasks_status ON tasks(status);
CREATE INDEX IF NOT EXISTS idx_tasks_priority ON tasks(priority);
`);
console.log('数据库初始化完成');定义数据访问层#
class TaskRepository {
constructor(db) {
this.db = db;
// 预编译常用语句
this.stmt = {
insert: db.prepare(`
INSERT INTO tasks (title, description, priority)
VALUES (@title, @description, @priority)
`),
update: db.prepare(`
UPDATE tasks
SET title = @title, description = @description,
status = @status, priority = @priority,
updated_at = CURRENT_TIMESTAMP
WHERE id = @id
`),
delete: db.prepare('DELETE FROM tasks WHERE id = ?'),
findById: db.prepare('SELECT * FROM tasks WHERE id = ?'),
findAll: db.prepare('SELECT * FROM tasks ORDER BY priority DESC, created_at DESC'),
findByStatus: db.prepare('SELECT * FROM tasks WHERE status = ? ORDER BY priority DESC'),
};
}
create(task) {
const result = this.stmt.insert.run({
title: task.title,
description: task.description || '',
priority: task.priority || 0,
});
return this.stmt.findById.get(result.lastInsertRowid);
}
update(id, task) {
this.stmt.update.run({ id, ...task });
return this.stmt.findById.get(id);
}
delete(id) {
return this.stmt.delete.run(id);
}
findById(id) {
return this.stmt.findById.get(id);
}
findAll() {
return this.stmt.findAll.all();
}
findByStatus(status) {
return this.stmt.findByStatus.all(status);
}
// 批量更新状态
updateStatusBatch(ids, status) {
const updateOne = this.db.prepare(
'UPDATE tasks SET status = ?, updated_at = CURRENT_TIMESTAMP WHERE id = ?'
);
const transaction = this.db.transaction((taskIds) => {
for (const id of taskIds) {
updateOne.run(status, id);
}
});
transaction(ids);
return ids.length;
}
}
const taskRepo = new TaskRepository(db);使用示例#
// 创建任务
const task1 = taskRepo.create({
title: '完成项目文档',
description: '编写 API 文档和使用指南',
priority: 2,
});
const task2 = taskRepo.create({
title: '代码审查',
description: '审查 PR #123',
priority: 1,
});
console.log('创建的任务:', task1);
// 查询所有任务
console.log('所有任务:', taskRepo.findAll());
// 更新任务状态
taskRepo.update(task1.id, { status: 'completed' });
console.log('更新后的任务:', taskRepo.findById(task1.id));
// 批量更新
taskRepo.updateStatusBatch([task1.id, task2.id], 'in_progress');
console.log('批量更新后:', taskRepo.findAll());
// 按状态查询
console.log('进行中的任务:', taskRepo.findByStatus('in_progress'));
// 删除任务
taskRepo.delete(task2.id);
console.log('删除后:', taskRepo.findAll());注意事项与最佳实践#
并发写入处理#
SQLite 的写操作是串行化的,高并发写入可能导致锁等待。以下是一些应对策略:
// 1. 使用 WAL 模式提升并发读性能
db.pragma('journal_mode = WAL');
// 2. 批量写入减少锁竞争
const insertMany = db.transaction((tasks) => {
const stmt = db.prepare('INSERT INTO tasks (title) VALUES (?)');
for (const task of tasks) {
stmt.run(task.title);
}
});
insertMany([
{ title: '任务1' },
{ title: '任务2' },
{ title: '任务3' },
]);
// 3. 合理设置 busy_timeout
db.pragma('busy_timeout = 5000'); // 等待 5 秒
性能优化技巧#
预编译语句缓存 better-sqlite3 会自动缓存预编译语句,但显式创建语句可以进一步优化:
// 重复使用的查询预编译
const getActiveUsers = db.prepare('SELECT * FROM users WHERE active = ?');合理使用索引 为常用查询条件创建索引:
db.exec('CREATE INDEX IF NOT EXISTS idx_users_email ON users(email)');批量操作 使用 transaction 包装批量操作:
const batchInsert = db.transaction((data) => {
const stmt = db.prepare('INSERT INTO items (name) VALUES (?)');
for (const item of data) {
stmt.run(item.name);
}
});调整 PRAGMA 参数
// 提升写入性能
db.pragma('synchronous = OFF'); // 危险:可能丢失数据
db.pragma('journal_mode = MEMORY');
// 提升读取性能
db.pragma('cache_size = -64000'); // 64MB 缓存
db.pragma('temp_store = MEMORY');错误处理#
try {
db.prepare('INSERT INTO users (name) VALUES (?)').run('测试');
} catch (error) {
if (error.code === 'SQLITE_CONSTRAINT') {
console.log('违反约束:', error.message);
} else {
console.error('数据库错误:', error);
}
}
// 使用 verbose 选项调试 SQL
const db = new Database('app.db', {
verbose: (sql) => console.log('SQL:', sql),
});资源清理#
// 关闭数据库连接
db.close();
// 或者使用 try-finally 确保清理
function withDatabase(callback) {
const db = new Database('app.db');
try {
return callback(db);
} finally {
db.close();
}
}总结#
SQLite 作为一款轻量级但功能完整的嵌入式数据库,在众多场景中展现了其独特的价值。而 better-sqlite3 则为 Node.js 开发者提供了一个高性能、易用的 SQLite 访问接口。其同步 API 设计让代码更加清晰直观,卓越的性能表现使其成为处理中小型数据存储需求的理想选择。
在实际项目中,SQLite + better-sqlite3 的组合特别适合:本地数据持久化、开发测试环境、快速原型开发、轻量级桌面或移动应用等场景。当然,对于需要处理高并发写入或超大规模数据的应用,仍然需要考虑使用传统的关系型数据库。
掌握 better-sqlite3 的核心 API 和最佳实践,将帮助你在项目中更高效地处理数据存储需求。开始尝试在你的下一个项目中集成 SQLite 吧!